
El año pasado Google implementó algunos cambios en su crawler que afectaron de pleno a la construcción del archivo robots.txt. Hoy analizamos estos cambios, empezando por el principio: qué es y para qué sirve robots.txt, cómo definirlo en tu web y cómo usar este pequeño archivo para mejorar el SEO de tu página. ¡Vamos a ello!
Robots.txt: qué es y para qué sirve
Robots.txt es un pequeño archivo de texto plano que contiene las instrucciones sobre indexación de nuestro sitio web. Este archivo se coloca en el directorio raíz del dominio, y habitualmente es accesible desde la URL dominio.com/robots.txt.
La función principal del archivo robots.txt es dar instrucciones a los bots o arañas de los buscadores (los software que rastrean tu web) sobre la rastreabilidad e indexabilidad de nuestra página web. Habitualmente cuando pensamos en un bot pensamos en el de Google o Bing, pero también nos podemos referir a herramientas como Sistrix, Screaming Frog o Semrush – cada una de ellas tiene su propio software de rastreo, y el archivo robots.txt sirve para dar instrucciones a todos ellos.
¿Cómo se construye un robots.txt?
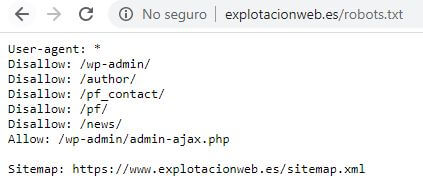
User-agent: es como llama el archivo a los robots. Al utilizar el Asterisco, indicamos que las siguientes instrucciones valen para todos los robots. Si solo quisiéramos indicar algo al bot de Google, pondríamos user-agent: Googlebot.
Allow / Disallow: Son los dos comandos principales. Allow recomienda el acceso, y Disallow lo deniega. Con un comando por línea, seguido de dos puntos y la URL o directorio conseguimos mandar la señal a los diferentes bots – aunque la última decisión es siempre del software de rastreo (es decir, por mucho que hagamos disallow en un directorio, si Google considera que tiene que indexarlo lo acabará indexando. Pero habitualmente hace caso). En el ejemplo, intentamos bloquear el acceso a las páginas de login y autor entre otras.
Sitemap: Como el archivo robots.txt es visita obligatoria a los user agents en el caso de que esté, muchos (entre los que nos incluimos) aprovechan para poner un enlace hacia el sitemap de la web. De esta manera seguro que no se pierden 😉
Sencillo, ¿verdad?
Subir un archivo robots.txt a mi web
Aunque hay varios plugins para crear tu robots.txt e incluirlo automáticamente en la raíz de tu directorio, la manera más sencilla de hacerlo es escribiéndolo en tu blog de notas, guardando el archivo con extensión .txt y subiéndolo al archivo raíz de tu sitio vía FTP o por código.
Cambios en la araña de Google que afectan a robots.txt
Además de los comandos antes mencionados, había un tercer comando que era muy utilizado: Noindex. Este permitía que los user agents leyesen esos directorios pero sin indexarlos en los buscadores.
Sin embargo en septiembre de 2019 Google dejó claro que este comando ya no tendría ningún tipo de efecto. El objetivo de esta medida era estandarizar el uso de robots.txt a través del Robot Exclusion Protocol, que solo contempla los comandos allow y disallow. Si quieres evitar la indexación de una página, tendrás que hacerlo a través de las metaetiquetas o a partir de otras soluciones más creativas, como poner esa página o directorio detrás de una contraseña.
Relación entre robots.txt y SEO
Y algunos os estaréis preguntando… ¿Y todo esto qué tiene que ver con el SEO?
Pues muchísimo. Tener un archivo robots.txt correcto es uno de los primeros pasos que debemos tomar a la hora de revisar el estado SEO y de indexación de nuestra página web. ¡Podría ser que no estuviera indexada o posicionando correctamente por tener en disallow todo el dominio! Imagínate. Qué desastre, qué mal todo.
Si quieres que nosotros nos encarguemos de revisar tu página web para asegurarnos de que todas estas bases están cubiertas, no lo dudes y ponte en contacto con Explotación Web. También puedes pedirnos tu informe SEO gratuito para que hagamos un análisis personalizado de tu dominio y tengas herramientas para empezar a mejorarlo. Y como siempre, gracias por leernos.
ENTRADAS FRESCAS




